
I recently worked with a large financial services organization to analyze a data breach scenario and determine the potential risk reduction (in terms of dollars and cents) that would result from implementing tokenization on key fields within a database cluster containing PII information.
recently worked with a large financial services organization to analyze a data breach scenario and determine the potential risk reduction (in terms of dollars and cents) that would result from implementing tokenization on key fields within a database cluster containing PII information.
Determining the relative reduction in risk with the FAIR model – used by the RiskLens cyber risk quantification software – requires that you:
- first establish a baseline risk analysis (current state),
- isolate the factor(s) within the model that are impacted by the control enhancement (e.g., tokenization), and
- then create a new version of the baseline analysis with the revised values that reflect the impact of the change (future state).
In this case, the baseline risk scenario involved a database breach of PII records by a cyber criminal, where data was stored in plain text.
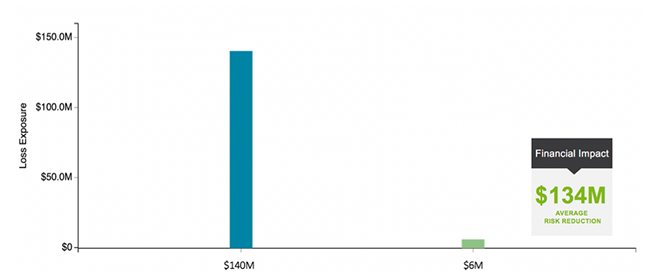
Analysis Results
The below report depicts the high-level results of the organization’s data breach risk analysis. The current state in blue depicts the organization’s average loss exposure (risk) on an annualized basis given the current estimations of frequency and magnitude (10+M records) of the breach event. The magnitude of the loss assumes that the data left the organization in plain text. The green bar depicts the anticipated loss exposure in the event that key PII fields were to be tokenized. The impact is a $134M reduction in loss exposure; a powerful figure that can be compared against the cost of the investment to make an informed business decision.

Milestone for the FAIR Community: Membership in the FAIR Institute Passes 3,000
Setting Up the Risk Analysis
When assessing the amount of risk associated with a breach of sensitive data belonging to customers (a common type of risk analysis we help financial services organizations conduct), the organization is likely to experience what is referred to in the FAIR model as Secondary Loss. Secondary Loss is any loss that materializes as a result of negative reactions from external stakeholders.
I’ve often reflected control enhancements such as encryption or tokenization in the model by adjusting the Secondary Loss Event Frequency (SLEF) factor, which is the percentage of times that you expect to experience a fallout due to secondary stakeholders. SLEF is a great way to quickly model the impact of a fallout from secondary stakeholders. However, there may be times where your SLEF may change for various loss types at a different degree.
Circling back to the example I cited above, the organization was only planning to implement tokenization on the most sensitive fields in the database cluster (e.g., Social Security number and Taxpayer Identification Number), while leaving the remaining fields such as name, address, and phone number (phone-book type information) unmasked.
In this instance, changing the SLEF would not be the most accurate indicator of the change in fallout resulting from secondary stakeholders, as certain elements of secondary loss may slightly reduce while others may be eliminated altogether.
Therefore, we modeled this change by directly altering the magnitude of the various types of secondary loss. We created a new version (or copy) of the Loss Tables within the RiskLens platform and adjusting the values based how the loss would materialize in the event that SSN and Tax ID were tokenized.
The benefit of manipulating the Secondary Loss Event Magnitude (SLM) values vs. changing the Secondary Loss Event Frequency (SLEF) is that you are able to isolate the degree at which the various types of loss are expected to materialize as a result of a fallout from secondary stakeholders.
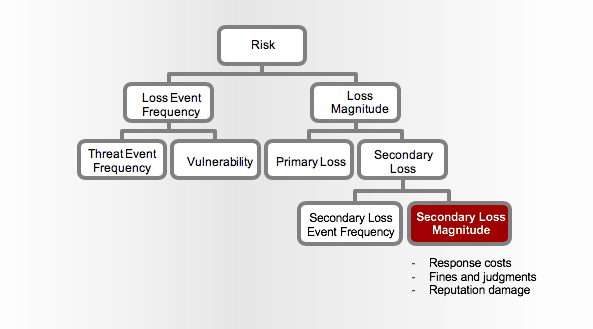
Modeling the Reduction in Risk
Below is an example of how we modeled the reduction in risk from implementing tokenization using Secondary Loss Magnitude:
Loss Types with Significant Decrease in Loss Magnitude
When discussing the impact, we noted that the following items would substantially be reduced to an immaterial amount as a result of implementing tokenization on SSN and Tax ID:
- Customer Notification– represents the cost of distributing formal notification customers affected by the data breach (ex: printing and mailing). According to the Corporate Communications department, there would be no loss here since customer notification would not contractually be required if only customer phone book information was exposed.
- PR/Marketing– represents campaign efforts to publicly respond to the data breach. The Marketing team acknowledged that if the breach only involved an exposure of customer phone book data and not SSNs or Tax IDs, it would be highly unlikely that additional PR / Marketing resources would be leveraged to create a campaign to publicly respond to the event. Additional funds may only be allocated in the event of a large-scale breach (greater than 1M records) involving exposure of SSNs.
- Litigation– reflects the cost of litigation activities related to the data breach. According to the Head of Litigation, if the breach involved exposure of phone book data and no SSN or Tax IDs, it is reasonable to assume that no material expenditures would result from litigation fees to defend the organization from lawsuits initiated by external parties.
- Fines and Judgments– represents fines and judgments paid to regulators and other third parties as a result of a data breach. Per conversations with the Head of Litigation, if the data breach only involved exposure of phone book data, it is reasonable to assume that material fines and judgments from various regulatory entities is unlikely to occur. Many of the significant fines that are publicly available in the financial services industry are related to breaches of SSNs. Further, it is important to note that, per discussions with legal and compliance, the database cluster only contained information about US customers and, through their analysis, determined to be out of scope for GDPR.
Values for the above types of loss were set to zero (or a very small number) to reflect certain types of loss that would likely not materialize as a result of tokenizing SSN.
Gartner Names Risk Quantification a Must-Have for Integrated Risk Management
Loss Types with Slight Decrease in Loss Magnitude
Contrary to the above items, the remaining costs associated with secondary response would still apply when phone book data is exfiltrated in plain text; although not to the degree if all fields (including SSN and Tax ID) were not tokenized:
- Credit Monitoring– represents the offer and pickup cost of credit monitoring / identity management services for affected customers. Per discussion with Legal and Privacy, we determined that the organization is still contractually committed to offer credit monitoring even when only customer phone book information was exposed. The adoption rate; however, would likely be less than if SSNs were revealed.
- Regulator Notification– reflect the level of effort involved from Legal and Compliance to determine which regulatory entities require notification and the states in which they reside. Per conversations with the Legal department, their team is engaged as soon as incident is determined to be a breach. In the event that only customer phone book data is exposed, the team still incurs time researching and determining which regulatory entities would need to be notified. In the event certain entities require notification, additional time would also be incurred both by legal and compliance to draft the response. The additional amount of time to draft notifications would represent the maximum cost of regulator notification.
- Reputation – estimates loss associated with customers taking their business elsewhere as a result of the loss event. Per discussions with client relations, if the data exposed were limited to customer phone book data, it is reasonable to assume little to no attrition would occur. The small percentage of attrition would account for the retail customers that are less “sticky” and have a historically higher rate of attrition than the remaining customer base. This was reflected as a minimum attrition rate of 0% and a maximum of 0.01%. The minimum attrition rate if SSNs or Tax IDs were breached was assumed to be greater than 0% and the maximum increased by slightly more than the normal expected attrition rate.
Takeaways for Future Risk Analyses
Modeling the change in risk by directly changing the magnitude of various types of Secondary Loss is particularly beneficial when aiming for a better degree of precision, such as when the analysis is being used to make investment decisions. Using SLEF may still be fine when performing quick and dirty analyses (to prioritize risks) or when the different types of secondary loss will be impacted to the same degree. This exercise is just one of the many examples of the flexibility of the FAIR model. All it takes is the ability to think critically when presented with a given risk scenario.
Related:
4 Powerful Ways to Use the RiskLens Cyber Risk Quantification Platform