
 People in the cybersecurity profession are increasingly looking to quantitative risk management to help them have objective conversations about cyber risk. It’s not surprising why. The spotlight on cybersecurity continues to grow and business people are understandably concerned about the impact a security incident may have on business operations. Not to mention, as resources continue to be invested in cybersecurity programs, they’re anxious to understand the value that’s being provided.
People in the cybersecurity profession are increasingly looking to quantitative risk management to help them have objective conversations about cyber risk. It’s not surprising why. The spotlight on cybersecurity continues to grow and business people are understandably concerned about the impact a security incident may have on business operations. Not to mention, as resources continue to be invested in cybersecurity programs, they’re anxious to understand the value that’s being provided.
As a result, it’s not surprising that interest in FAIR™ (Factor Analysis of Information Risk) and risk quantification has ballooned over the past 18 months. The FAIR standard has been recommended by the NIST CSF, the National Association of Corporate Directors Cyber Risk Handbook, and the COSO Enterprise Risk Management Framework. The RiskLens platform is the only enterprise-scale SaaS application for FAIR cyber risk quantification.
Joe Vinck is a Strategic Account Executive for RiskLens
When I’m working with customers beginning with FAIR, one of the first steps we’ll complete is a walkthrough of a few risk scenarios in the RiskLens platform. This is a basic exercise where we can demonstrate how we scope a scenario, how the RiskLens software can request and provide the relevant data, and ultimately how it generates a quantitative risk report. Given RiskLens is entirely based on the FAIR standard, every piece of data fed into RiskLens aligns with a factor of FAIR.
Check out this screenshot of a RiskLens workshop to see what I mean.
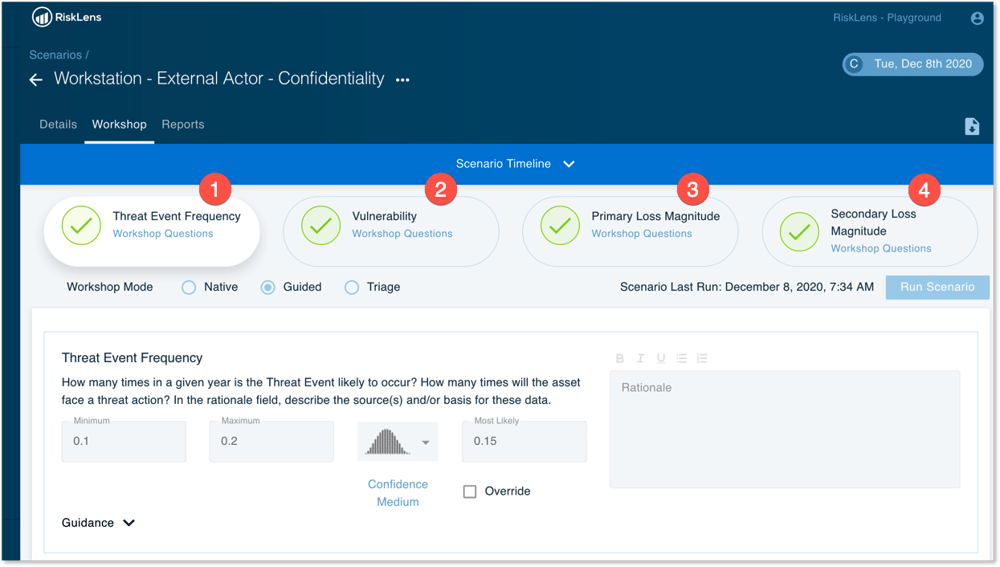 We’ll get more into this later, but adherence with FAIR provides rigor and defensibility to have confidence in the outputs.
We’ll get more into this later, but adherence with FAIR provides rigor and defensibility to have confidence in the outputs.
But what happens if we don’t have confidence in the data we’re inputting?
Especially for those who are less familiar with FAIR, this is not all that uncommon. Whenever a client shares that they’re struggling with trusting the data within a FAIR analysis, there are a few things I encourage them to remember.
We are not trying to predict the future with a cyber risk analysis
We’re trying to gain a financial understanding of our biggest security gaps so we can make the best security decisions. This is a representation and forecast based upon the best possible data we can find. It’s meant to enable a better discussion than subjective risk assessment approaches and helps us to identify what are the most likely events that could happen so we can prioritize and justify security investments most effectively.
FAIR cyber risk quantification training through the RiskLens Academy - learn more.
In FAIR risk quantification analysis, every data input and reporting output is expressed in a range
This allows us to account for our uncertainty. This is not a problem if we understand it and incorporate it into our communication and decision-making processes when presenting to stakeholders. Most companies’ sales forecasts are expressed in a range to factor uncertainty, so it’s not a foreign concept for most. We’re looking for accuracy in a range not precision (which can be precisely wrong).

It’s a bit of a goofy exercise, but there’s a simple question I could ask to help drive this home:
If you had to bet $1000, how tall would you guess I am?
Yep, Joe Vinck, the author of this blog.
As you’re reading this you can make some assumptions despite probably never having met me in person.
- Assumption #1: It’s extremely unlikely I’d be over 8' tall or under 4' tall
- Assumption #2: You could go to LinkedIn, verify I’m an adult male, and Google that the average male is 5’ 9”
- Assumption #3: If you’re feeling crazy and want to keep digging, you could Google me (no need to, just trust me on this one), find out I played high school and college sports, and assume that I’m above average height
After all of that, most people would feel comfortable betting that I’m somewhere between 5’ 5” - 7'.
While it’s a simple example, this is the thought process we teach customers as they complete FAIR analyses. We take a question we often don’t know the answer to, then apply some critical thinking, document our assumptions, and arrive at an answer in a range. Take a few minutes to think about how you’d approach finding data for these questions related to cybersecurity:
- How many phishing emails do we receive every month?
- When outage of our billing system occurs, how many hours will it be down?
- How many times per year do we expect a customer facing system to go down due to an insider error?
For more assurance, RiskLens provides industry risk data out of the box
 Realistically, you may not be able to collect all the best data on cyber loss events and costs within your organization. Experts may be unavailable or unsure themselves of the answers. Not to worry.
Realistically, you may not be able to collect all the best data on cyber loss events and costs within your organization. Experts may be unavailable or unsure themselves of the answers. Not to worry.
Having worked with many organizations to operationalize FAIR, RiskLens has curated catalogs of data like risk scenarios, frequency information, control efficacy data, threat intel, and fines & judgments data to simplify the risk assessment process. We augment our catalogs with data from trusted suppliers such as the Verizon DBIR and Advisen.
Here’s one very specific example: If you're running a ransomware analysis and the RiskLens platform asks, “What capital or operational expense costs would be incurred to replace the asset(s) at risk?”, rather than hunting the information down yourself from industry data sources or colleagues, we provide average pay-out measures directly in the platform.
Even if industry data isn’t leveraged for your analysis, it provides a helpful baseline for facilitating a conversation. If the average capital or operational expense related to a ransomware incident is $300k, that’s a great data point to know. Should we expect ours to be higher? Lower? Or in line with the average?
This is why industry data is so powerful at speeding up and driving defensibility in risk analysis.
For those still on the edge of their seats, I’m 6’1”
See cyber risk quantification in action on the RiskLens platform. Schedule a demo.